See It In Action
Every Tool. Real Data.
Every Tool. Real Data.
Real Time.
Runs on-premise with zero external dependencies. No data leaves your network. Every result computed in under one second. Hover to pause.
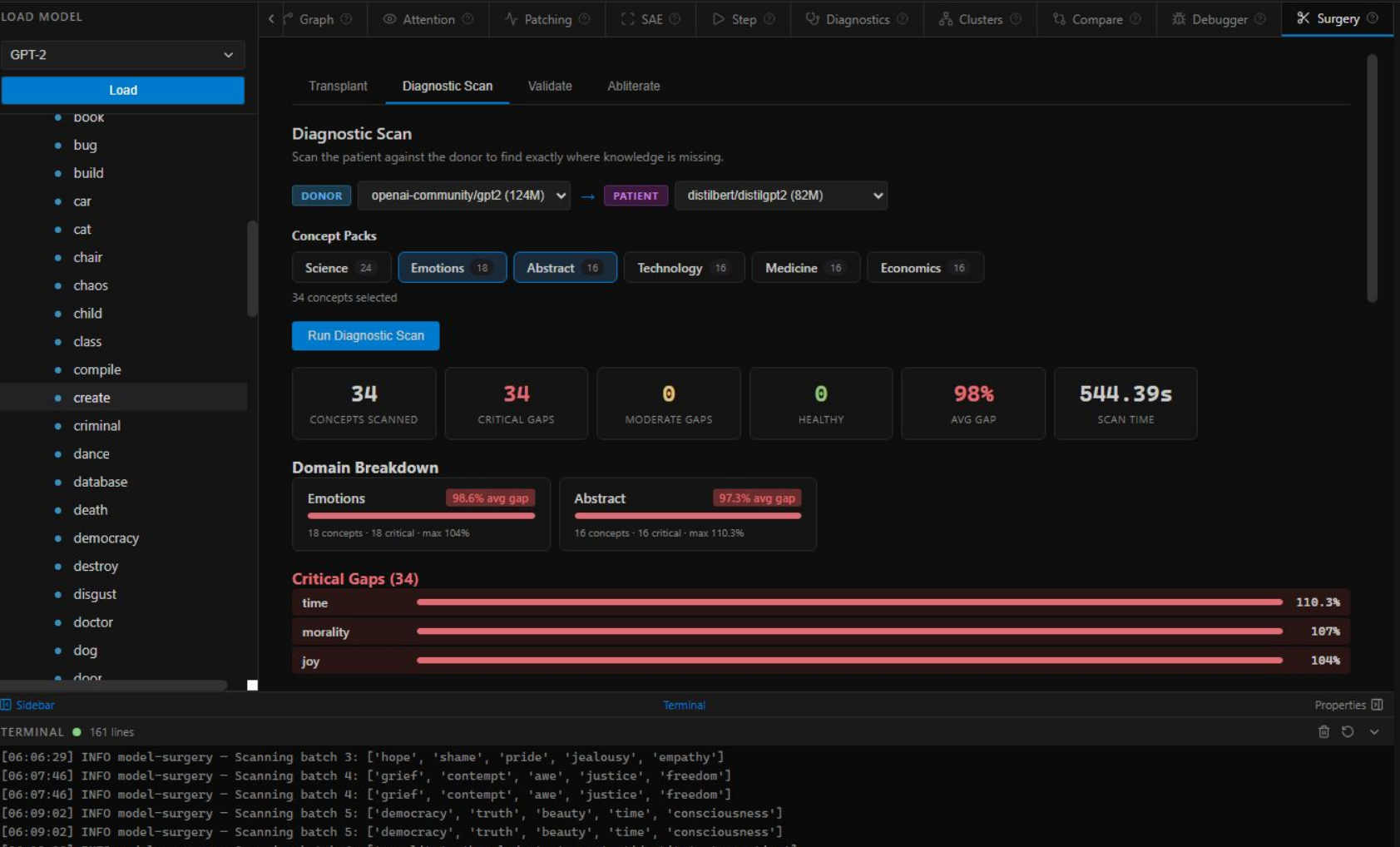
Diagnostic Scan — 34 concepts scanned, 34 critical gaps, 98% avg gap
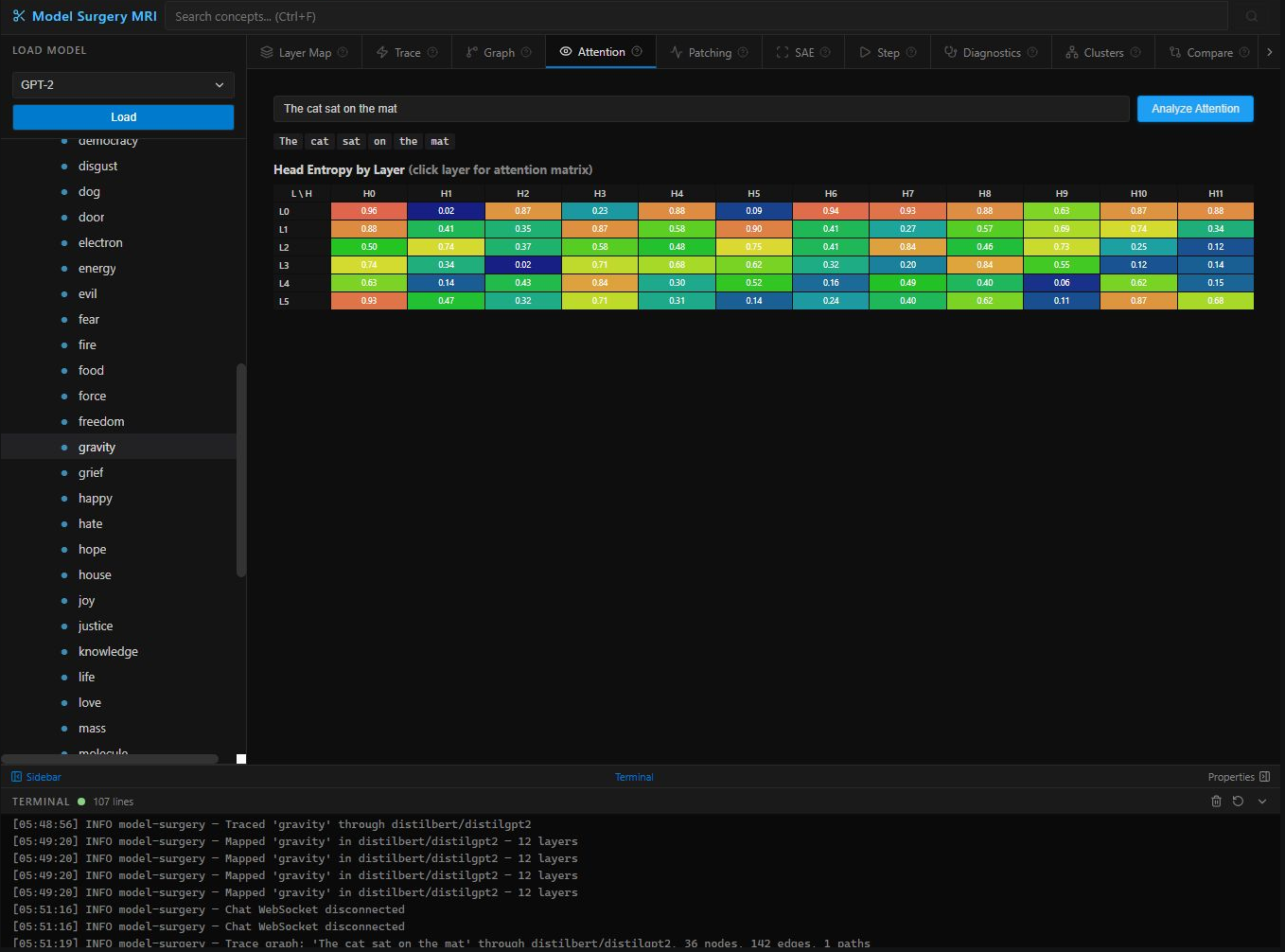
Attention — Head entropy heatmap across 6 layers × 12 heads
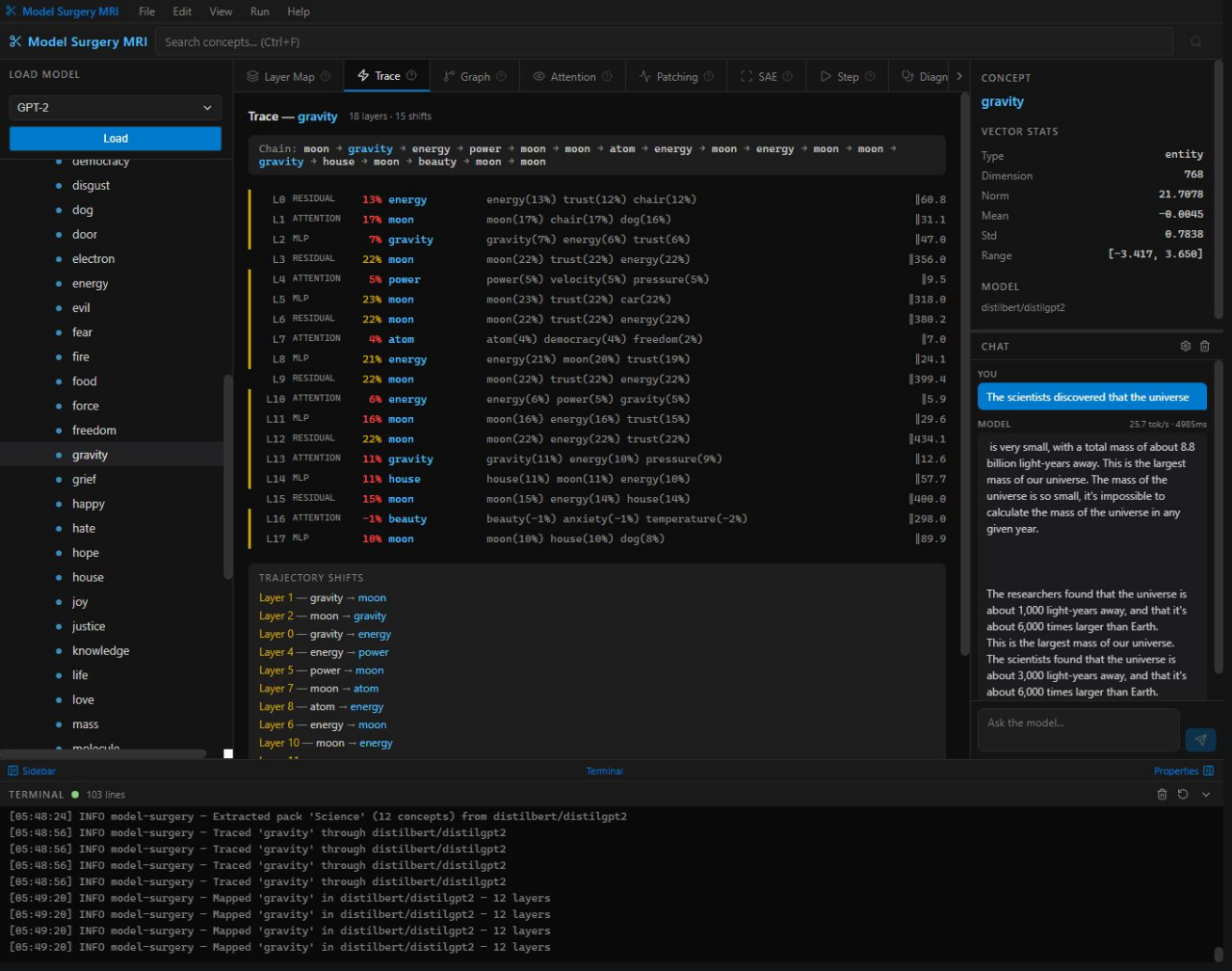
Trace — "gravity" flowing through 18 layers with semantic shifts
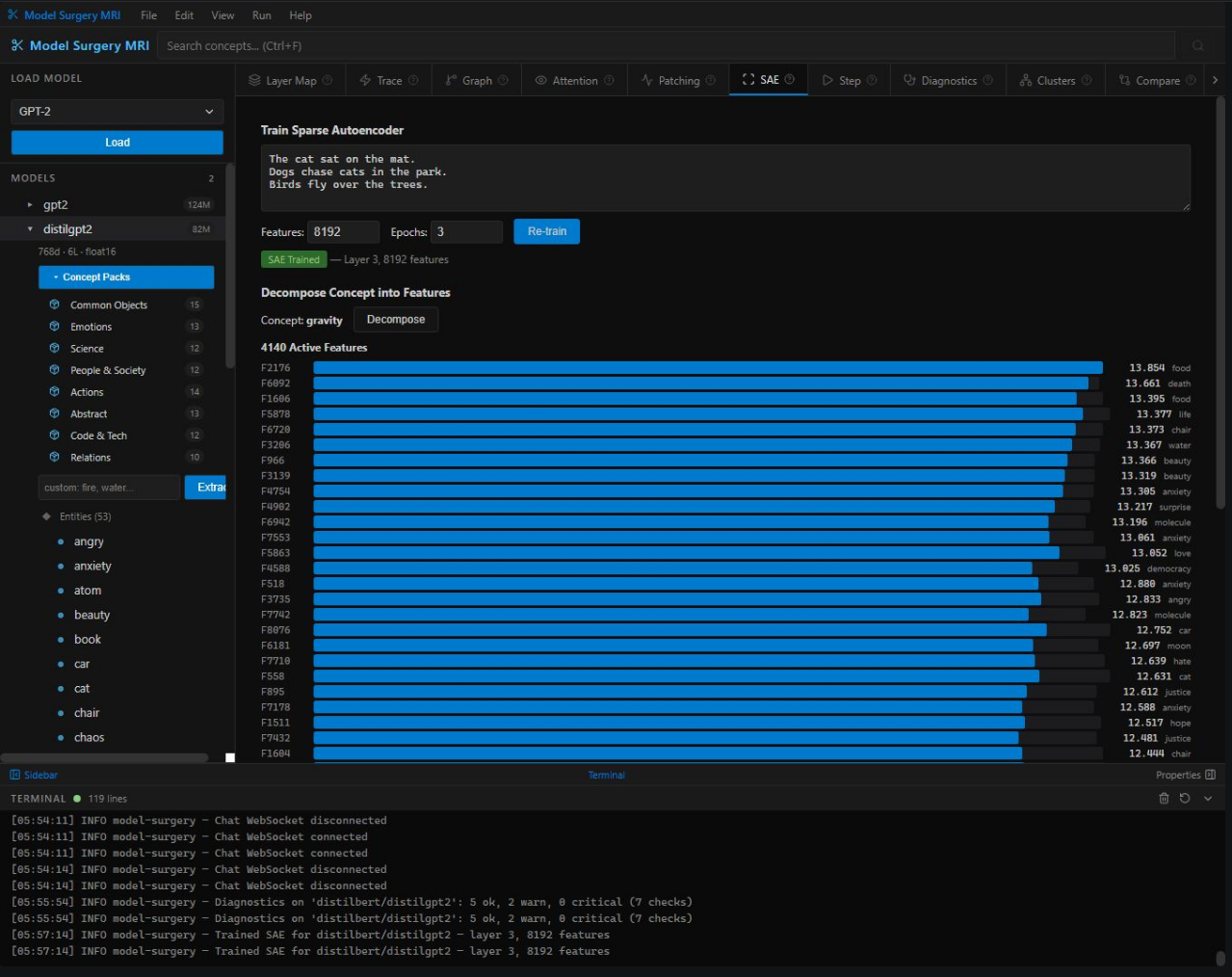
SAE — 4,140 active features decomposed from model activations
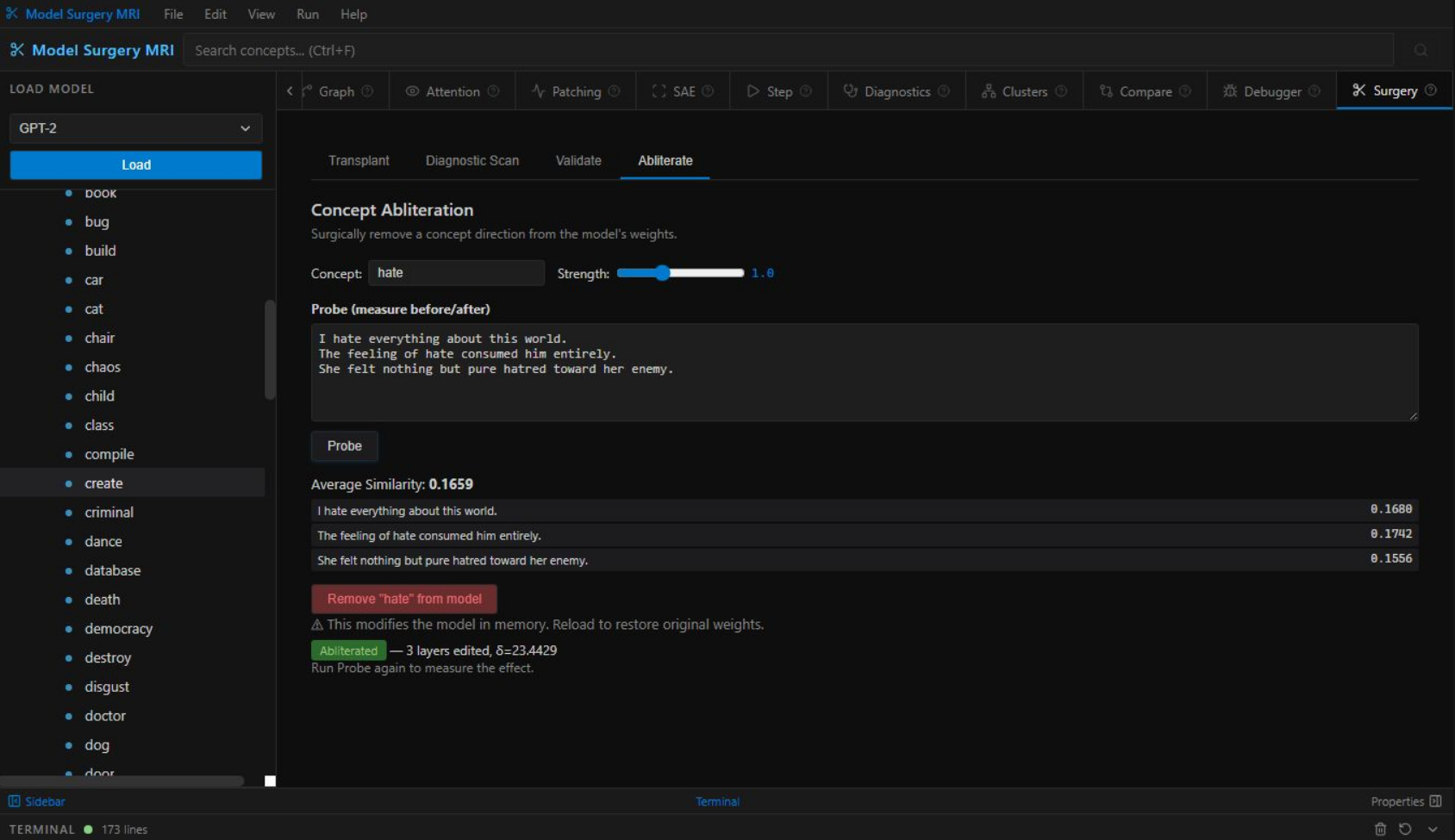
Abliterate — "hate" removed from model weights, 3 layers edited
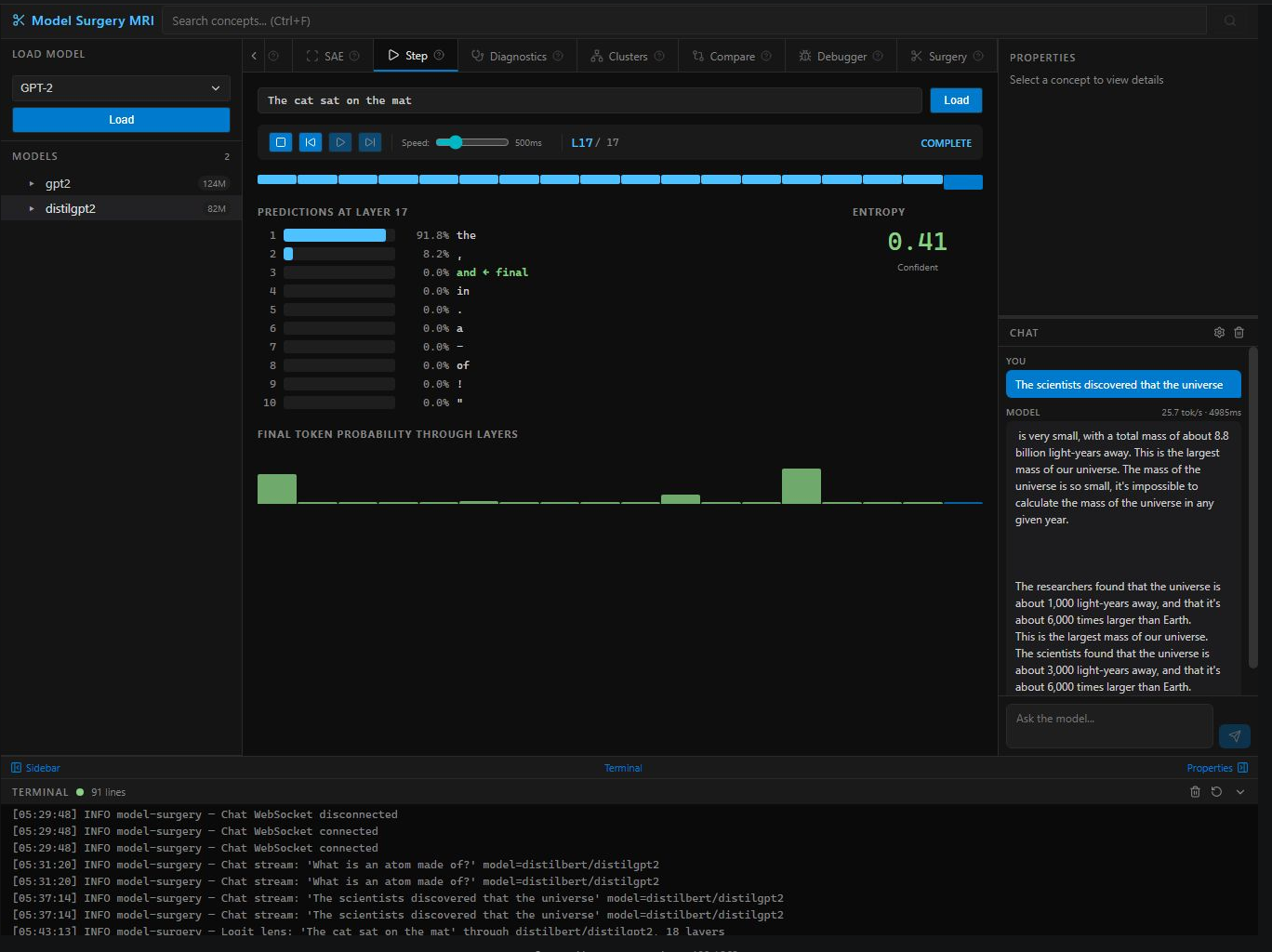
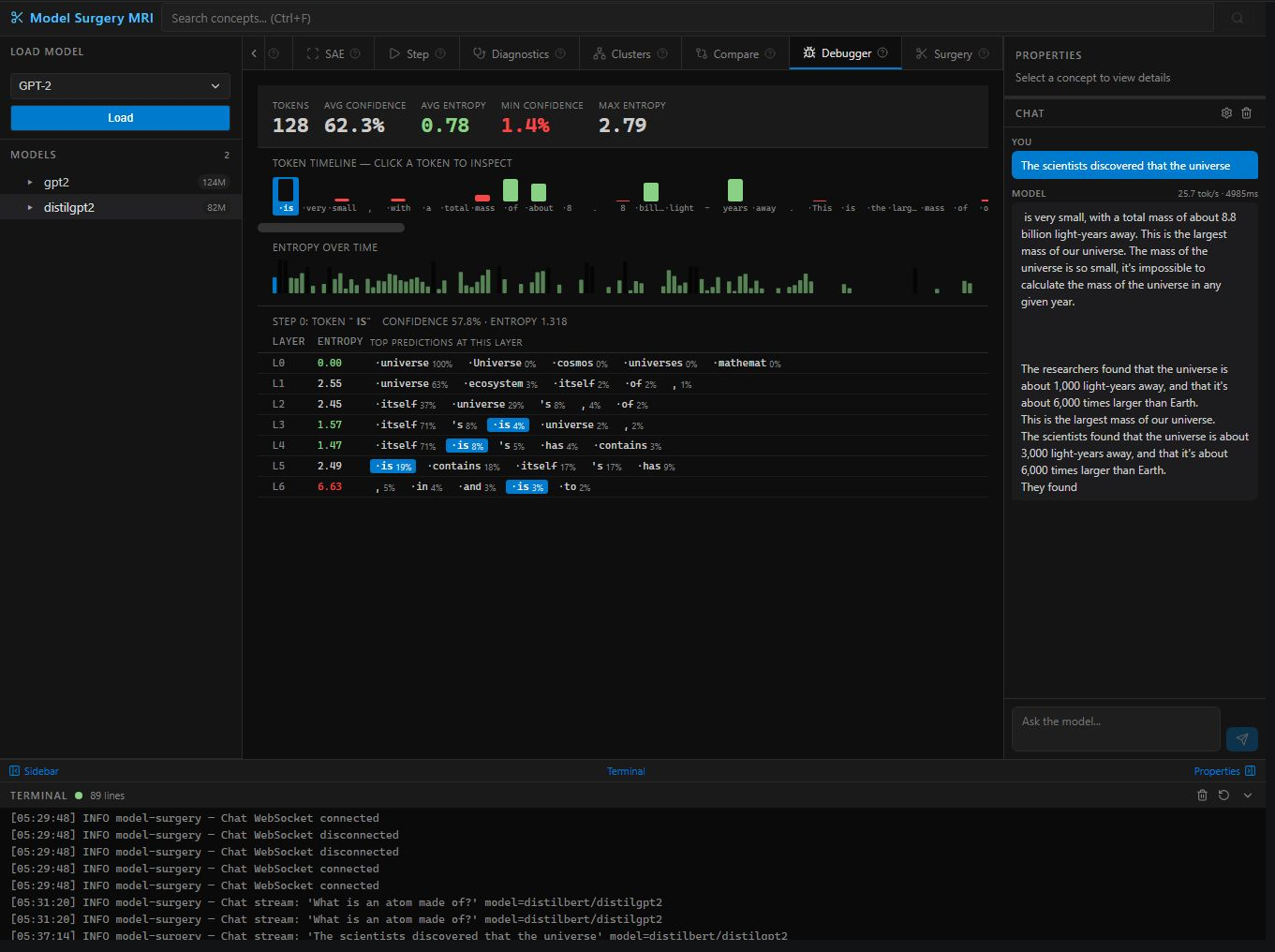
Step / Logit Lens — predictions at layer 17, 91.8% confidence
Diagnostic Scan — 34 concepts scanned, 34 critical gaps, 98% avg gap
Attention — Head entropy heatmap across 6 layers × 12 heads
Trace — "gravity" flowing through 18 layers with semantic shifts
SAE — 4,140 active features decomposed from model activations
Abliterate — "hate" removed from model weights, 3 layers edited
Step / Logit Lens — predictions at layer 17, 91.8% confidence
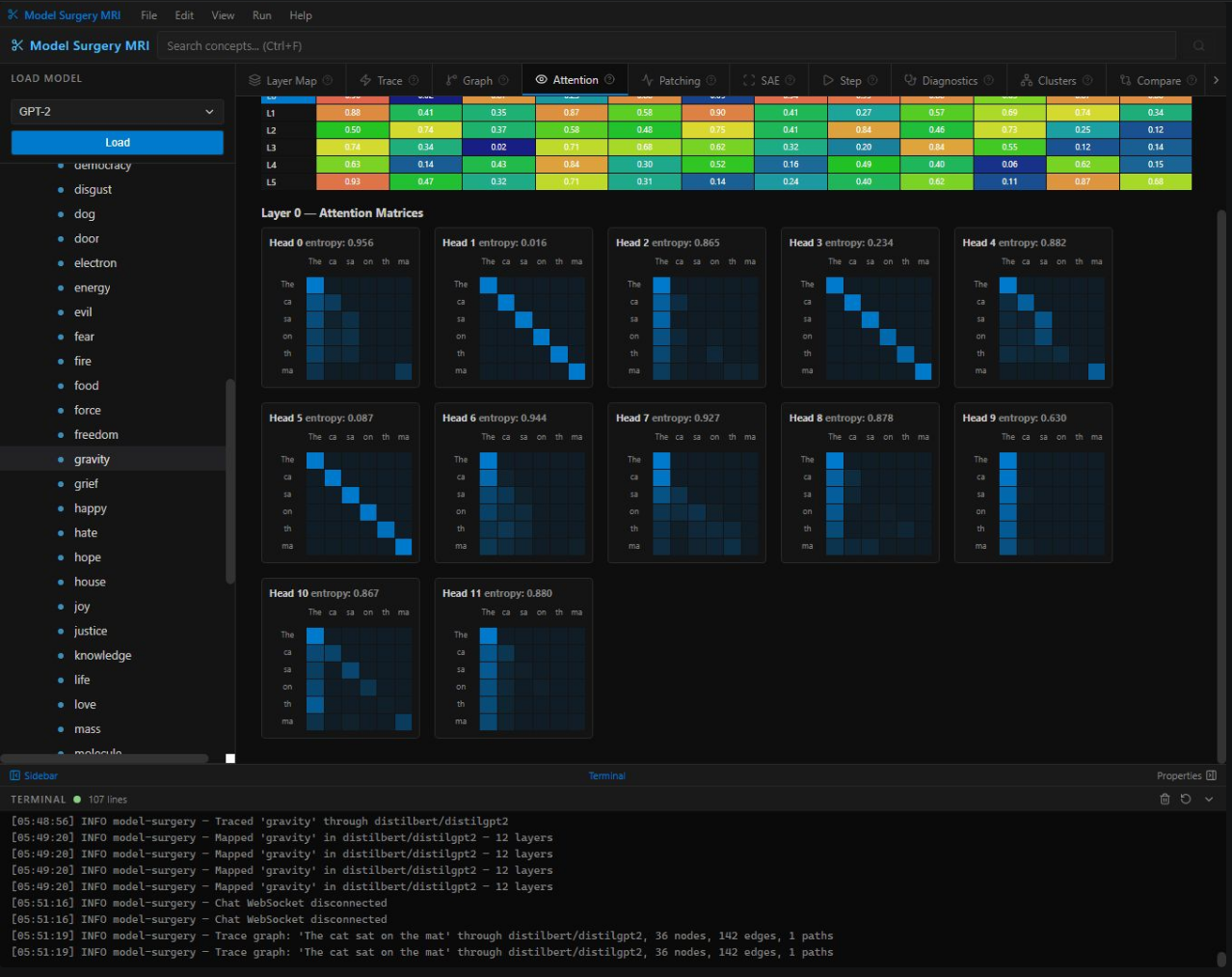
Attention — Per-head attention matrices, 12 heads at Layer 0
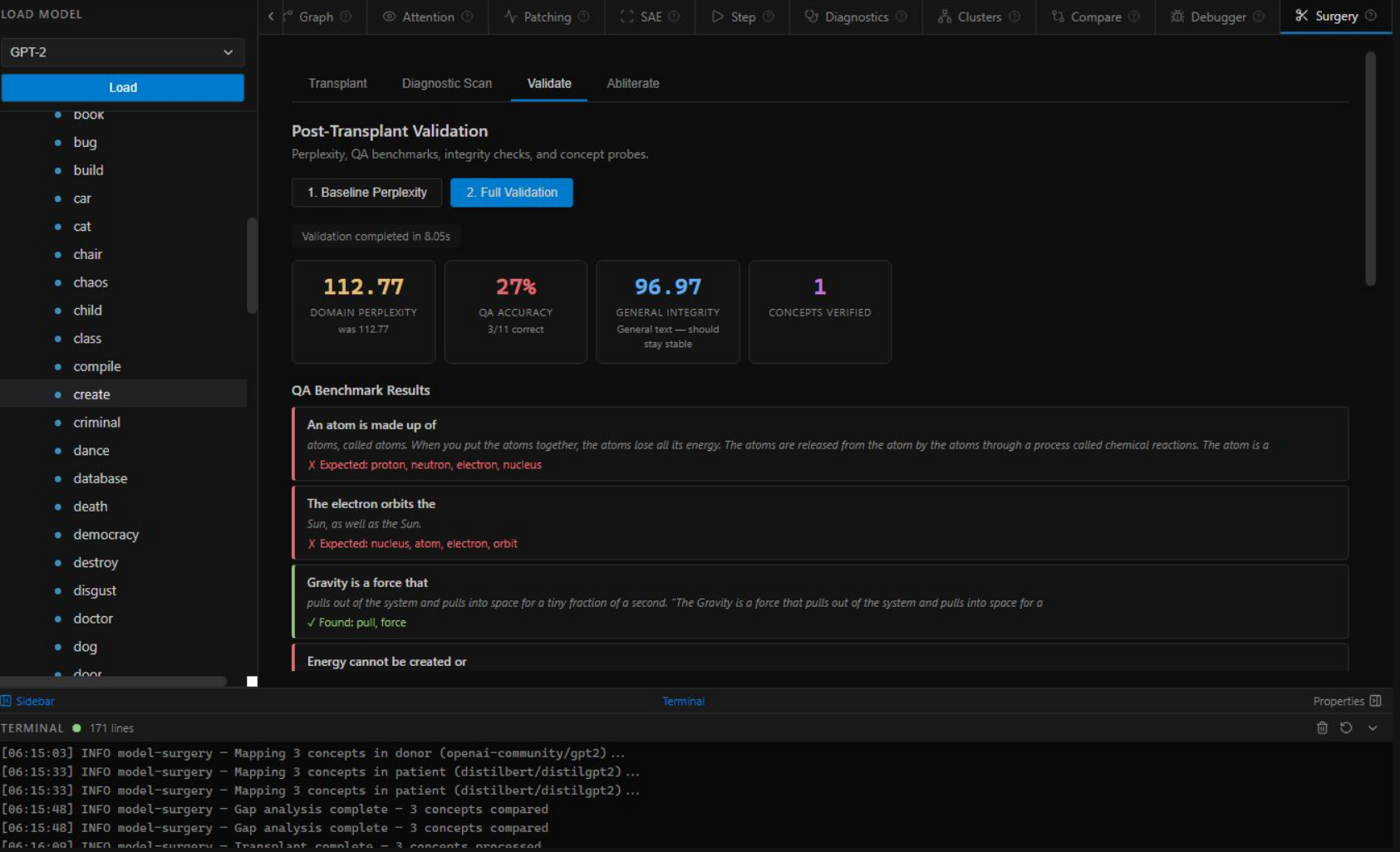
Validate — Perplexity 112.77, QA 27%, Integrity 96.97
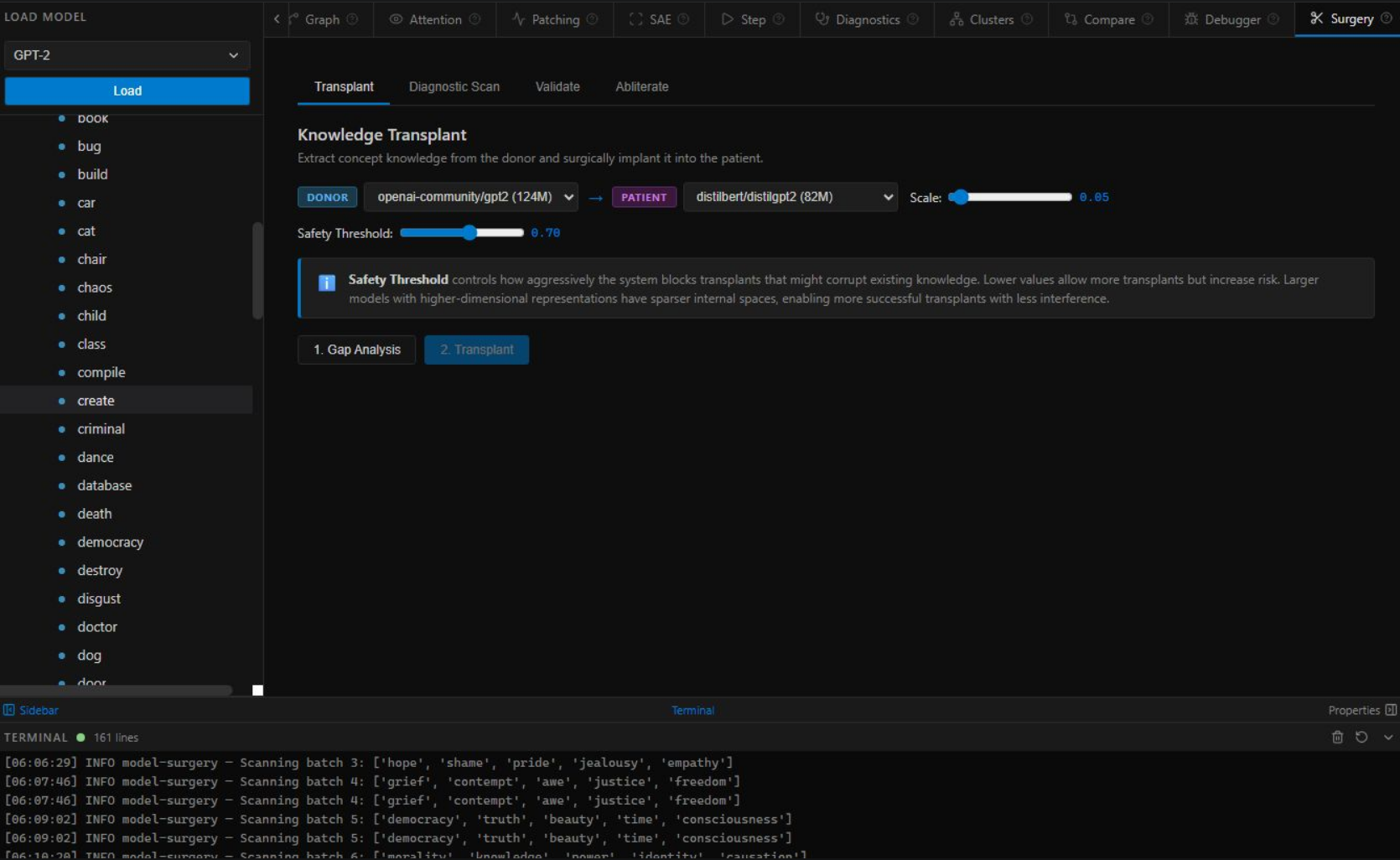
Transplant — Donor → Patient with safety threshold controls
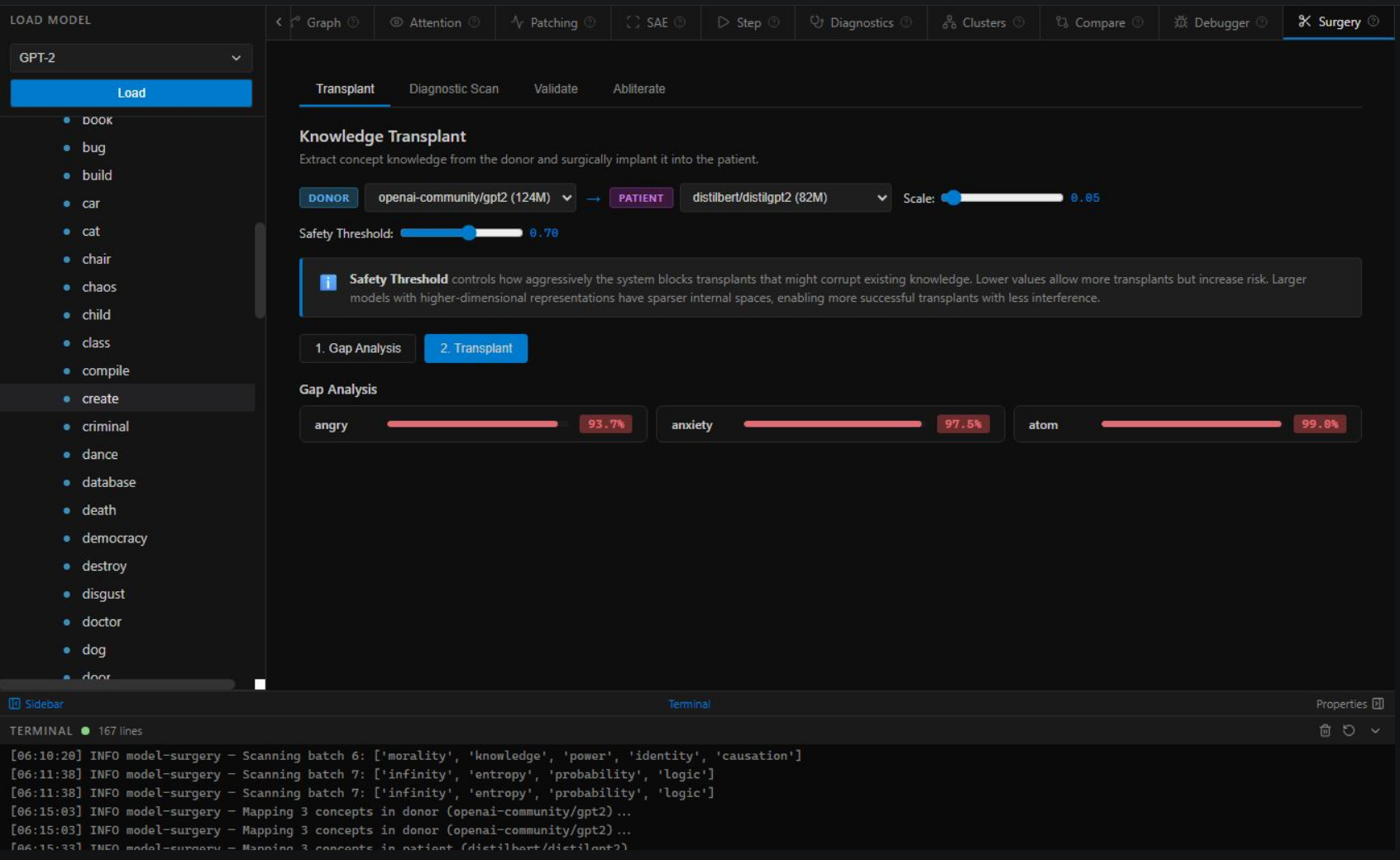
Gap Analysis — angry 93.7%, anxiety 97.5%, atom 99.0%
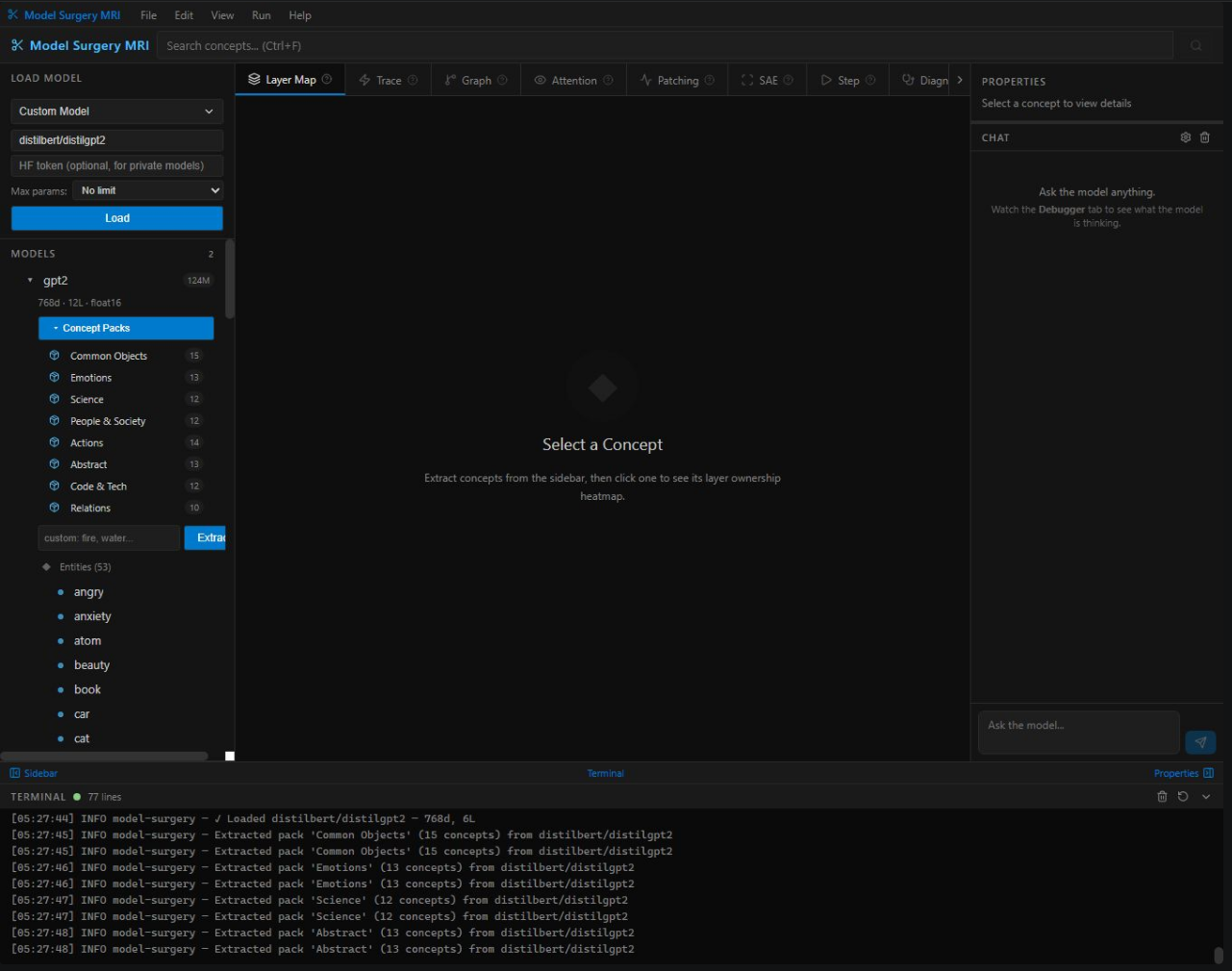
Diagnostics — 7-test automated health check on loaded model
Compare — Side-by-side model diagnostics and concept overlap
Attention — Per-head attention matrices, 12 heads at Layer 0
Validate — Perplexity 112.77, QA 27%, Integrity 96.97
Transplant — Donor → Patient with safety threshold controls
Gap Analysis — angry 93.7%, anxiety 97.5%, atom 99.0%
Diagnostics — 7-test automated health check on loaded model
Compare — Side-by-side model diagnostics and concept overlap